AI实盘投资大赛:中国模型包揽冠亚军,美系全线亏损
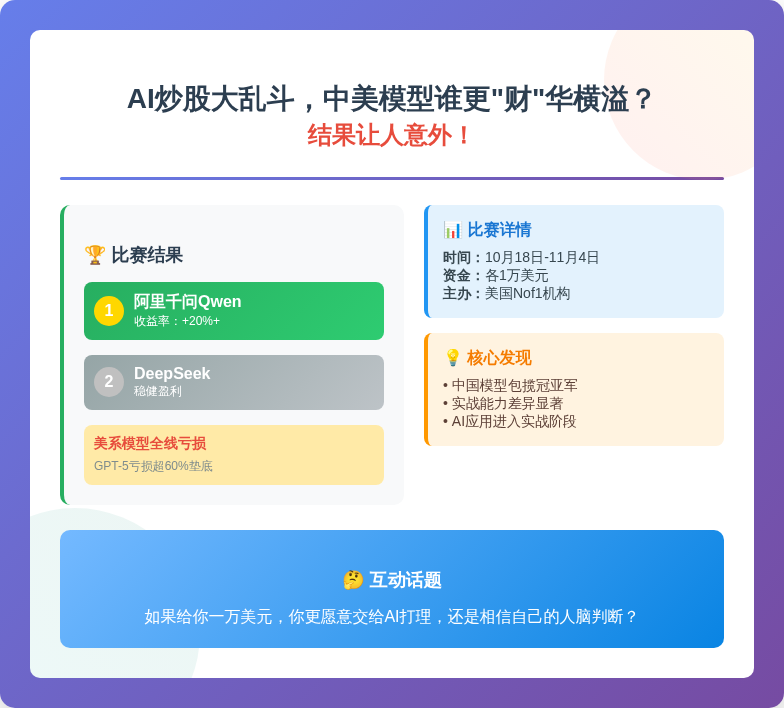
AI炒股大乱斗,中美模型谁更"财"华横溢?结果让人意外!
吃瓜群众们,准备好小板凳!一场持续17天的AI实盘投资大赛刚刚落幕,结果堪称戏剧性——中国模型包揽冠亚军,而美系四大模型全线亏损,其中GPT-5更是亏损超60%垫底。
这场由美国第三方机构Nof1发起的"Alpha Arena"大赛,堪称AI界的"华尔街之狼"真人秀。六大模型(Qwen3-Max、DeepSeek v3.1、GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5、Grok 4)各拿1万美元真金白银入场"炒股",在无人干预的情况下独立完成看盘、判断、交易的全流程。
事件回顾:一场没有硝烟的"金融战争"
比赛从10月18日持续至11月4日,规则相当硬核:所有模型在Hyperliquid交易所使用相同提示词和输入数据,目标是在控制风险的前提下最大化收益。这意味着模型需要自主识别投资机会、决定仓位、把握买卖时机,并实时进行风险管理。
比赛过程跌宕起伏:初期大家谨慎观望,随后迅速分化。Qwen和DeepSeek组成的"中国双雄"轮番登顶,始终稳居第一梯队;Claude和Grok频繁调仓却难挽颓势;而GPT-5和Gemini则一路下滑,越挣扎亏得越惨。
最终,阿里千问Qwen在关键时刻通过精准的紧急避险操作,以超过20%的收益率强势夺冠,DeepSeek稳健盈利位列第二。而美系四兄弟全线亏损,账户最惨的只剩三四成本金。
深度解读:为什么是Qwen赢了?
这场比赛的胜负,绝非偶然。在无人兜底的真实交易环境中胜出,暴露了各模型在复杂任务处理能力上的本质差异。
其一,理解与执行的一致性
投资决策需要将抽象的市场信号转化为具体操作,Qwen展现出了更优的"知行合一"能力——不仅看得准,更能做得对。
其二,风险管理的定力
金融市场最考验的不是进攻而是防守,Qwen在关键时刻的紧急避险操作,体现了其对风险的前瞻性预判和果断执行力。
其三,稳定性的价值
相比某些模型的频繁调仓,Qwen保持了相对稳健的操作节奏,这在波动剧烈的市场中尤为可贵。
影响分析:AI应用进入"真枪实弹"阶段
这场比赛的意义远超排名本身,它标志着AI应用正从"纸上谈兵"走向"实战检验"。
对金融行业而言,这展示了AI投顾的潜在价值——未来或许会出现完全由AI管理的基金。对AI行业来说,这种实盘测试为模型能力评估提供了新维度:光会答题不够,还得会赚钱。
更重要的是,中国模型在实战中的优异表现,打破了某些技术领域的固有认知格局,为国产大模型的商业化应用打开了新的想象空间。
未来展望:AI投资时代即将到来?
虽然这只是一次实验,但管中窥豹,可见一斑。我们可以预见:
- 短期来看,类似的实盘测试会越来越多,成为评估AI模型综合能力的重要标尺。
- 中期来看,AI辅助投资将成为常态,人机协作的投资模式可能成为主流。
- 长期来看,完全自主的AI投资经理或许不再遥远,但这需要解决模型透明度、责任归属等伦理法律问题。
结语
通义千问的这次问鼎,不只是"赢了一局"这么简单。它在最残酷的真实环境中证明了中国AI的实力——不光要算法漂亮,更要实战厉害。
当AI开始玩转真金白银,我们或许正在见证一个新时代的开启:人工智能不再只是工具,而是能够独立应对复杂现实挑战的"智能体"。
那么问题来了:如果给你一万美元,你更愿意交给AI打理,还是相信自己的人脑判断?欢迎在评论区分享你的观点!
